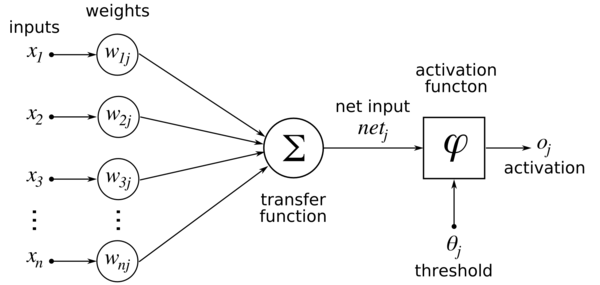
SRE Agent: доверять нельзя контролировать
Где поставим запятую? 🙂 или Как не дать автономному агенту положить прод и при этом не отстать от жизни Последние полгода мои коллеги (и не только коллеги) разделились на два лагеря. Одни с ужасом рассказывают, как их AI-SRE-агент случайно положил базу данных, потому что «просто хотел помочь с таймаутами». Другие восторженно показывают дашборды, где инциденты…