
SLI Compass: точность и детализация
Ментальная модель для оценки существующих SLI и новых
Оригинал: SLI Compass: Fidelity and Granularity by Alex Ewerlöf
Индикатор уровня обслуживания (Service Level Indicator, SLI) — основополагающая концепция в области обеспечения надёжности. При правильном применении он количественно оценивает уровень обслуживания с точки зрения пользователя в соответствии с бизнес-целями.
Однако разные SLI имеют разное соотношение сигнал/шум и ROI (окупаемость инвестиций).
В этой статье представлен SLI Compass — двумерная ментальная модель, которая поможет:
- Быстро оценить соотношение сигнал/шум существующих SLI
- Оценить SLI по их стоимости и сложности
- Установить направление для улучшения качества существующих SLI при разумной рентабельности инвестиций
Цель — помочь старшим инженерам, техническим и инженерным руководителям выбрать правильную SLI с учетом зрелости продукта, бюджета, сроков и особенностей использования.
Категоризация SLI
За эти годы я рассмотрел сотни архитектур с десятками команд как в своих компаниях, так и для внешних клиентов.
По моему опыту наиболее распространенными SLI являются:
- Доступность (Availability): доступен ли пользователю сервис и может ли он пользоваться им для выполнения своих задач? Это, безусловно, самый распространённый SLI, за исключением асинхронных сервисов, таких как очереди, для которых другие метрики имеют больше смысла.
- Задержка (Latency): сколько времени занимает взаимодействие пользователя с сервисом? Это очень распространенная проблема для сервисов, ориентированных на пользователя, или сервисов с критической скоростью использования ресурсов, таких как фронтенд, API, базы данных, CDN, обработка очередей рабочих нагрузок и т. д.
- Показатель успешности (Success rate): как часто пользователям удаётся выполнить свою задачу? Это характерно для транзакционных сервисов, таких как REST API, пользовательских маршрутов и даже для очередей задач (например, очереди недоставленных сообщений).
- Эффективность (Efficiency): работает ли сервис с правильными компромиссами, которые имеют смысл для бизнеса? Например: не используем ли мы слишком много ресурсов GPU для бесплатных пользовательских запросов? Используется ли кэш? Обрабатываются ли задачи, поставленные в очередь? и т. д.
Существуют также другие узкоспециализированные показатели, такие как правильность (correctness), актуальность (freshness), релевантность (relevance) и т. д.
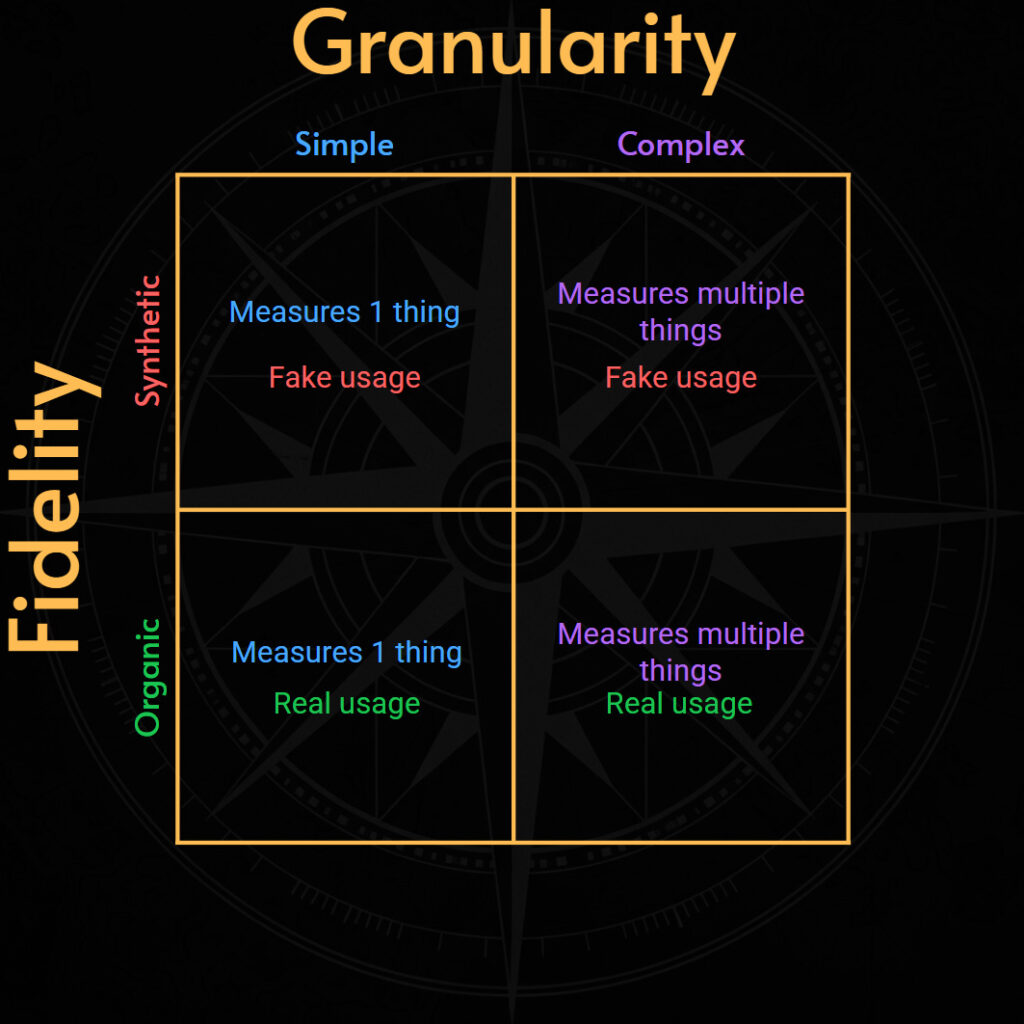
Все SLI можно отобразить на двумерной (2D) оси:
- Точность (Fidelity): насколько точно SLI отражает пользовательский опыт?
- Степень детализации (Granularity): сколько переменных и параметров агрегируются в одной точке данных?
Мы можем объединить эти два измерения, чтобы получить мощную, но знакомую модель квадранта.

Как мы увидим, одна категория SLI, например доступность или задержка, может вписаться в любой из этих 4 квадрантов.
Два измерения
1. Fidelity: насколько точно SLI отражает пользовательский опыт?
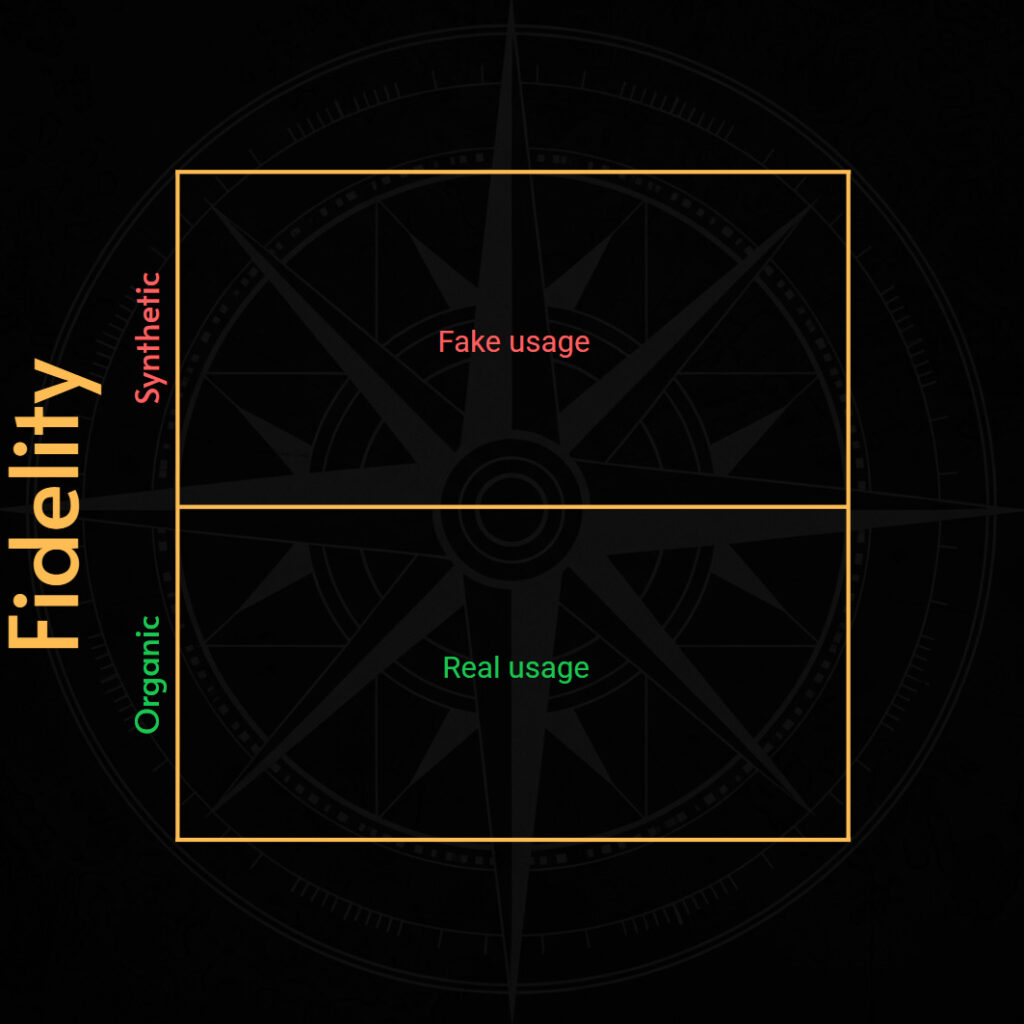
SLI Fidelity относится к тому, как генерируются данные (телеметрия) и насколько точно они отражают восприятие услуги пользователем.
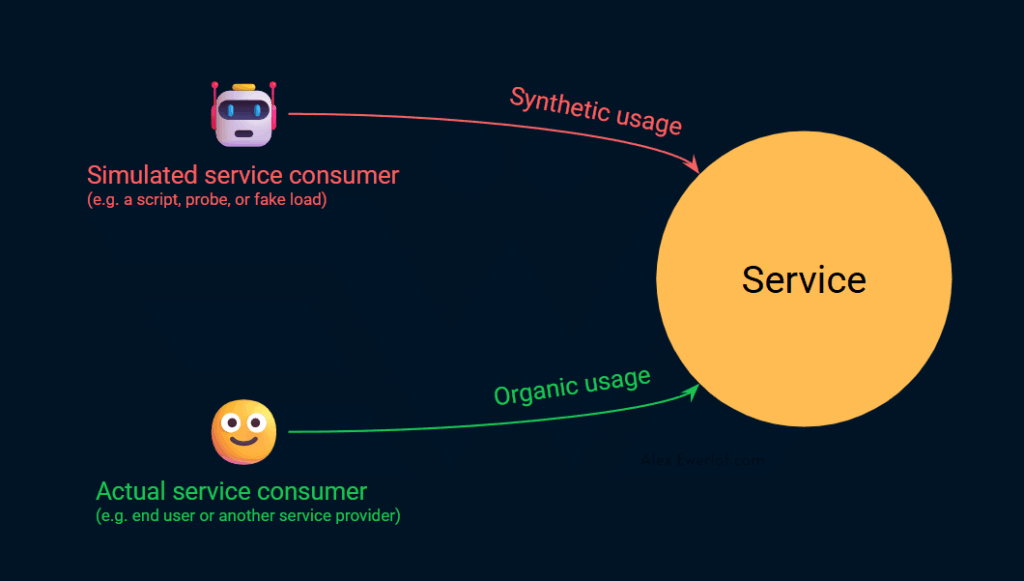
- Синтетические метрики используют искусственные, фиктивные или имитированные нагрузки. Типичным примером является инструмент, который каждую минуту отправляет запросы на эндпойнт для сбора данных о задержке или доступности. Эта проверка гарантирует, что эндпойнт отвечает.
- Органические метрики собирают данные от пользователей, которые фактически используют сервис. Например, мы можем собирать данные о доступности и задержках из API-шлюза, предоставляющего внешний доступ к сервису. Это более точный способ измерения уровня обслуживания.
Органические метрики более реалистичны. Они напрямую отражают то, что происходит с продуктом на проде.
Однако их сложнее измерить. Для сервисов с высоким трафиком они могут генерировать огромные объёмы данных. Это требует более надёжной и дорогостоящей инфраструктуры мониторинга.
Для сервисов с низким трафиком органической нагрузки может быть недостаточно для корректной работы формулы SLI. Это связано с тем, что статус SLI (также известный как SLS) рассчитывается в процентах.
Например, если сервис получает 50 запросов в месяц, неразумно ожидать 99% успеха, поскольку один сбой за этот период снижает статус уровня обслуживания (SLS) до 98%. В этом случае одним из решений может стать использование синтетической метрики.

Синтетическая нагрузка потенциально может исказить метрики продукта. Например, если продукт измеряет MAU (количество активных пользователей в месяц), важно иметь возможность отличать фиктивных (синтетических) пользователей от реальных. В противном случае неверные данные могут привести к принятию неверных решений.
2. Степень детализации: сколько переменных агрегируется точками данных SLI?
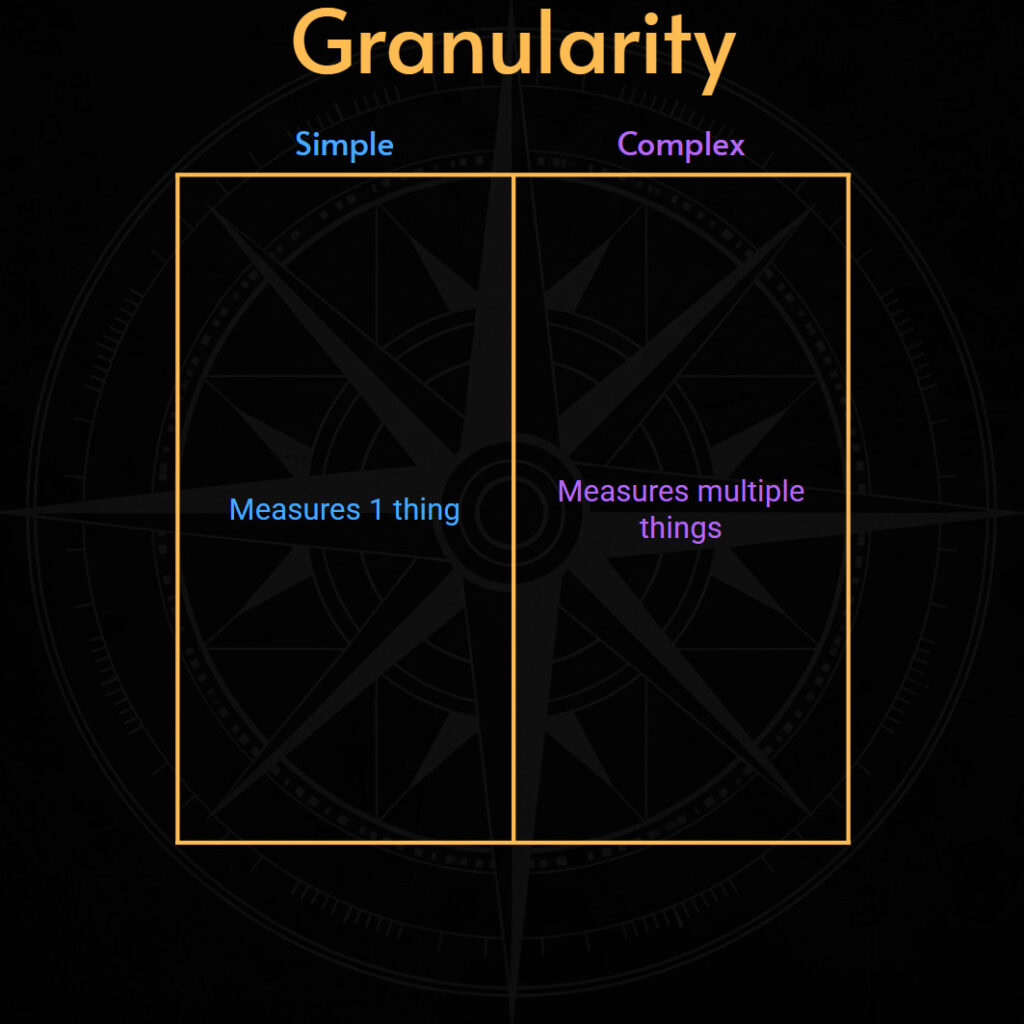
Давайте рассмотрим второе измерение SLI: их гранулярность, которая относится к числу параметров или переменных, проверяемых для количественной оценки уровня обслуживания.
- Простота: измеряйте только один параметр. Например, простая метрика может проверять, возвращает ли эндпойнт код статуса HTTP `200` (доступность) или задержка отдельного вызова API ниже порогового значения. Это позволяет оценить базовую работоспособность одного компонента. Она служит базовым индикатором общей работоспособности сервиса. Она не определяет, действительно ли сервис полезен для выполнения всей задачи пользователя.
- Комплексный подход: измеряйте множество показателей. Это позволяет получить более полную картину пути пользователя или поведения сложной системы. Высокоточная метрика может отслеживать успешность и задержку на всех этапах критически важного процесса. Она гарантирует, что всё работает так, как и ожидалось.
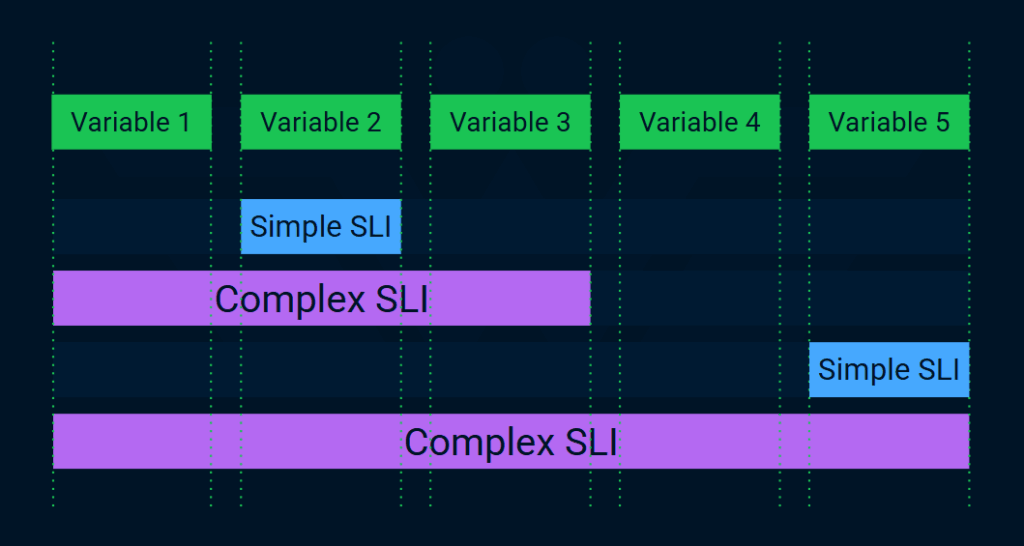
Комплексные, сложные SLI агрегируют несколько переменных. Например, вместо того, чтобы пинговать главную страницу (простой вариант), мы запускаем скрипт, который проходит по пути пользователя, чтобы выявить все неисправные этапы.
Комплексные SLI могут оказаться более дорогими в обслуживании.
Они также могут вызывать задержку в регистрации инцидента, поскольку им приходится ждать получения данных по всем переменным. Это потому, что необходима более глубокая обработка и агрегация данных.
Однако комплексные SLI обеспечивают более качественный сигнал, поскольку они более точно отражают пользовательский опыт.
С другой стороны, из-за агрегации может быть сложнее рассуждать о комплексных SLI: если произошел сбой, что именно и где произошло?
Чтобы ответить на этот вопрос, нам необходимо хранить больше данных, что увеличивает итоговую стоимость комплексных SLI.
Одним из недостатков сложных показателей SLI является использование разных переменных. Большинство метрик агрегируют сразу несколько переменных.
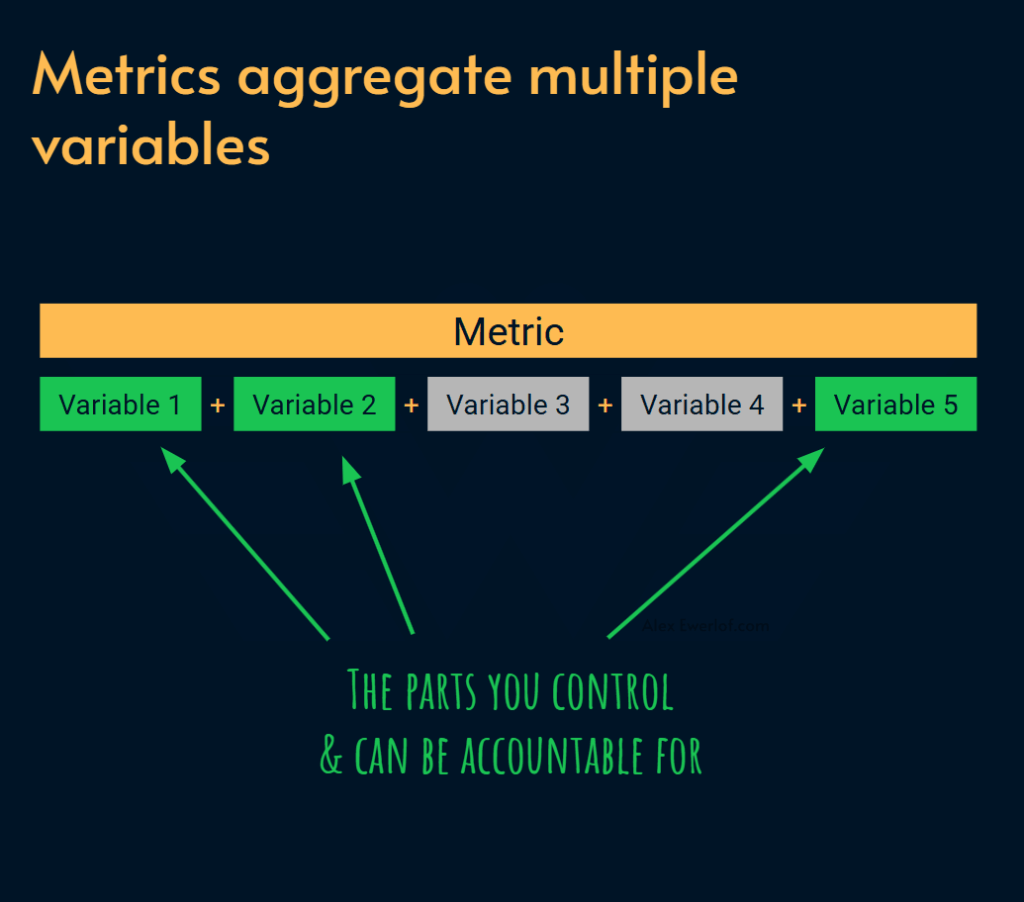
В идеале каждая точка данных должна агрегировать только переменные, находящиеся под контролем одной команды. Когда метрика показывает ухудшение или сбой в работе сервиса, легко понять, кто ответственен за этот сервис, и кому следует отправить уведомление для его устранения.
Собираем всё вместе
Собрав все вместе, получаем вот такой 2D-компас:
Примеры
Доступность — наиболее распространённый SLI. На базовом уровне это ответ на следующий вопрос:
Предоставляется ли услуга потребителю?
Однако можно задать более правильный вопрос:
Может ли потребитель использовать услугу для выполнения своих задач и достижения своих целей?
Разница тонкая, но важная:
- Первый вариант соответствует основным обязательствам **поставщика услуг** и обычно его легче измерить.
- Второй — соответствует ожиданиям **потребителя услуг** и, как правило, труднее поддается измерению.
Как можно измерить доступность API-сервера?
- Простой и синтетический: пингуйте конечную точку работоспособности каждую минуту и вычисляйте процент успешных пингов за [период](https://blog.alexewerlof.com/p/compliance-period)
- Простой и органичный: подсчитайте количество минут, в течение которых конечная точка API могла обрабатывать допустимые запросы (т. е. с допустимым заголовком аутентификации) за период.
- Сложный и синтетический: используйте синтетический мониторинг, чтобы проверить, работает ли критически важный пользовательский путь (например, процесс покупки), и вычислить процент успешного выполнения.
- Комплексный и органичный: используйте данные RUM (мониторинга реальных пользователей, real-user monitoring) для выявления любых прервавшихся пользовательских действий и расчета успешных пользовательских сеансов.
Давайте выполним это упражнение для задержки, которая является второй по распространенности SLI:
-
Простой и синтетический: Измерьте время ответа периодического
GETзапроса на заранее указанную конечную точку (т. е.www.example.com/api/health) и рассчитайте перцентиль P99 за период. -
Просто и органично: рассчитайте задержку P99-процентиля для всех успешных запросов API от реальных пользователей, измеренную на шлюзе API.
-
Сложный и синтетический: периодически моделируйте полную пользовательскую транзакцию (например, вход в систему, поиск, добавление в корзину, оформление заказа) и измеряйте время отклика от начала до конца.
-
Комплексный и органичный: анализируйте данные реального мониторинга пользователей (RUM), чтобы отслеживать время полной загрузки страницы, включая все выборки ресурсов и рендеринг для критически важных действий пользователя.
Соотношение сигнал/шум
Хорошие SLI стоит иметь под рукой, поскольку они с высокой точностью сигнализируют об ухудшении качества обслуживания или о сбоях . Даже если у вас дежурство не круглосуточное, для оценки SLI всё равно стоит придерживаться следующего подхода:
1. Помогает ли нам этот SLI получать уведомления об инцидентах? (в данном контексте инцидентом считается любой сбой, который ставит под угрозу бизнес-цель)
2. Указывает ли каждая аномалия в этом SLI на инцидент? (нет ложноположительных или ложноотрицательных результатов)
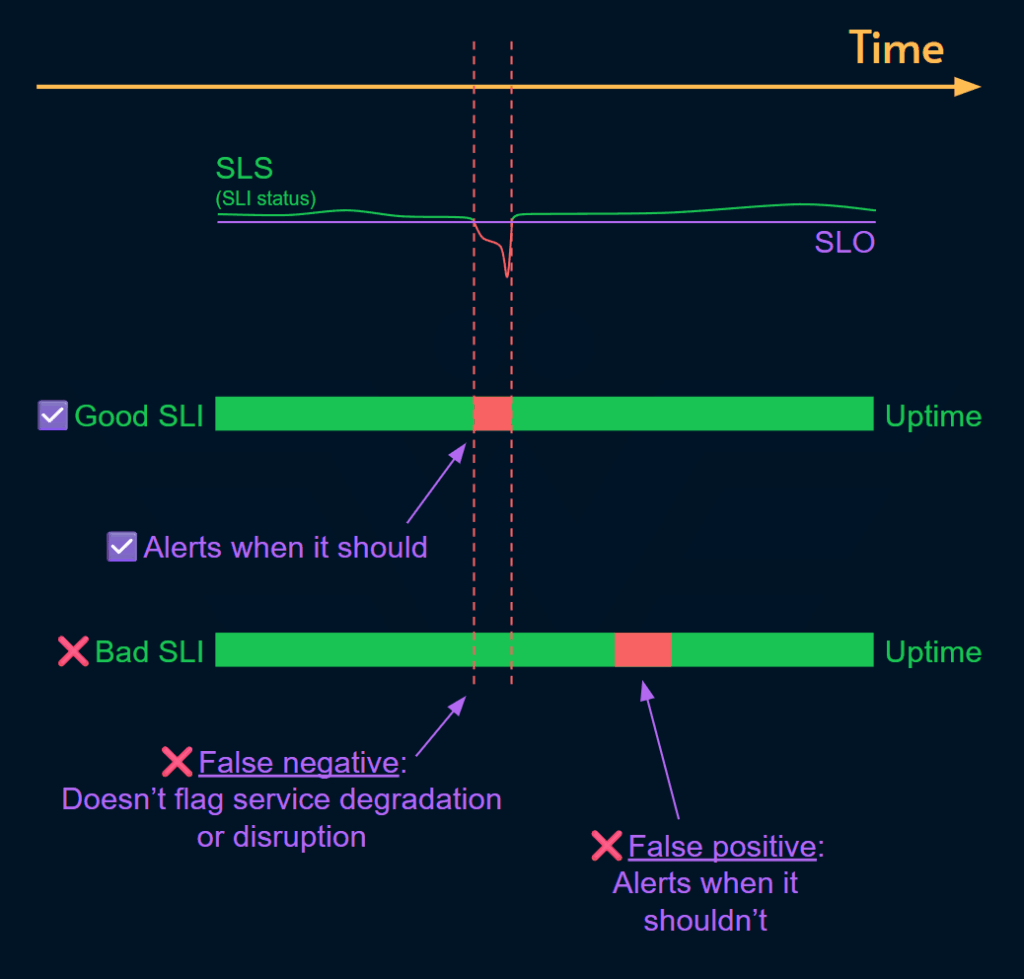
SLI — это основа для надежной реализации эффективного управления сервисом и ответственности за этот сервис:
SLI измеряет уровень сервиса с точки зрения потребителя.
SLO помогает:
- заинтересованным сторонам сформировать ожидания к владельцу сервиса
- владельцу сервиса четко обозначить свои обязательства перед пользователем
Алерты: связывают эти ожидания и обязательства с ответственностью.
Плохие SLI приводят к неэффективному управлению сервисом.





