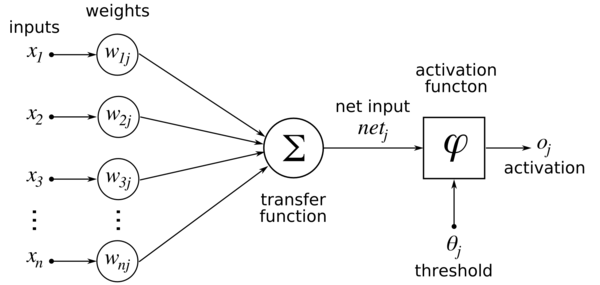
Что такое и как работает перцептрон
В 1957 году Фрэнком Розенблаттом был изобретен перцептрон — простейшая нейронная сеть и первая математическая модель нейрона мозга, которая принимает входные данные, обрабатывает их и выдает результат (например, «да» или «нет»). Как он работает? Входные данные — это числа (например, признаки объекта: вес, размер, цвет). Веса — каждый вход имеет свой «вес» (важность). Чем больше вес, тем…