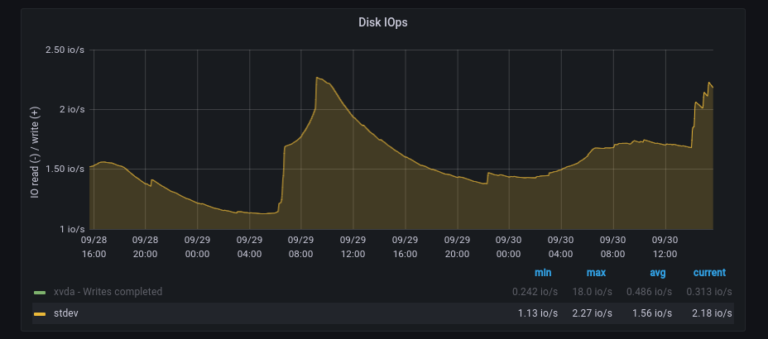
Каждая дополнительная «девятка» в SLO увеличивает надежность системы в 10 раз, но и одновременно увеличивает ее стоимость тоже в 10 раз (про реальность добавления «девяток» к аптайму).
Я называю это правилом «10x/9» (читается как «десять иксов на девятку»). Когда я впервые услышал об этом, мне показалось это подозрительным, но, взглянув на математику и вспомнив свой опыт, я понял, что удивительно, но это так и есть.
Каждая добавленная девятка
Давайте сначала разберемся с «девятками», прежде чем переходить к «10x».
Обычно SLO состоит только из девяток. Например: 99%, 99.9%…, но это необязательно, 99.5% — тоже валидный SLO. И даже 93%!, но обычно это так, так принято.
Когда SLO содержит только девятки, его можно сокращенно обозначить так:
- «Две девятки» = 99%. Бюджет ошибок = 1%.
- «Три девятки» = 99.9%. Бюджет ошибок = 0.1%.
- «Четыре девятки» = 99.99%. Бюджет ошибок = 0.01%.
- «Пять девяток» = 99.999%. Бюджет ошибок = 0.001% (уровень высокодоступных систем).
Я не работал с системами, где больше пяти девяток, но теоретически это возможно. Просто слишком дорого.
А что насчет 10x?
Надежность возрастает в 10 раз?
Возьмем простой пример: SLO на основе доступности (uptime).
Сервисы вроде uptime.is показывают, сколько простоя допускается:
- 99% — 7 часов 14 минут 41 секунда в год (25 920 секунд).
- 99.9% — 43 минуты 28 секунд (2 592 секунды).
- 99.99% — 4 минуты 21 секунда (259 секунд).
- 99.999% — 26 секунд.
- 99.9999% — 2.6 секунды.
Каждая добавленная девятка сокращает допустимый простой в 10 раз (т.е. повышает надежность).
Стоимость надежности
Чтобы повысить надежность, часто требуются огромные затраты:
- Рефакторинг: возможно, потребуется переписать код, чтобы погасить технический долг или использовать более надежный алгоритм. Иногда вы достигаете максимума возможностей языка программирования и можете подумать о том, чтобы переписать критически важные части сервиса на другом языке. Это не происходит в одночасье, планирование, изучение, рефакторинг, миграция требуют времени и сопряжены с реальными затратами на разработку.
- Реорганизация команд: если команда не настроена на обеспечение надежности, достижимый уровень надежности будет ограничен. Передачи задач между людьми увеличивают риск недопонимания и размывания ответственности.
- Изменение архитектуры: иногда требуется полностью переработать систему, чтобы она соответствовала новым нефункциональным требованиям, таким как масштабируемость, надежность и безопасность. Помимо прочего, может потребоваться резервное копирование или отработка отказа, добавление отказоустойчивости, добавление резервных систем переключения при сбоях.
- Увеличение производительности команды: если предполагается, что команда будет предоставлять фичи в том же темпе, одновременно повышая надежность, это потребует увеличения ресурсов. Например: больше более квалифицированных специалистов, меньше совещаний, более эффективные инструменты, более мощное оборудование, реплики баз данных, CDN и т.п.
- Снижение темпа разработки: изменения — главный враг надежности! Каждый раз, когда вы что-то изменяете в системе, вероятность аварии возрастает. Чтобы повысить надежность, может потребоваться замедлить выпуск новых функций, что потенциально вредит прибыли компании.
- Обучение сотрудников: чтобы повысить осведомленность о важности надежности, может потребоваться инвестировать в обучение. Обучение должно затрагивать не только рядовых сотрудников. Для реальных изменений необходимо, чтобы руководство и разработчики говорили на одном языке и рассматривали надежность как приоритетную задачу.
- Инструменты: системы мониторинга, управление инцидентами, ИИ-помощники и другие. Их внедрение требует затрат: покупка, обучение, настройка, интеграция, управление.
- Миграция: возможно, потребуется перенос рабочих нагрузок в более надежные системы или регионы, что усложняет репликацию, контроль доступа и безопасность.
- Инфраструктура: может потребоваться больше отказоустойчивых компонентов: мощные серверы, дополнительные экземпляры, реплики баз данных. Масштабирование (вертикальное или горизонтальное) стоит денег.
- Смена вендоров: сторонние поставщики или зависимости могут не соответствовать вашим требованиям к надежности даже за большие деньги. В таких случаях приходится менять поставщика или разрабатывать собственное решение.
- Время обнаружения (Time To Detect): время от момента возникновения проблемы до ее обнаружения. Для сокращения TTD может потребоваться автоматическое обнаружение инцидентов.
- Время устранения (Time To Resolve): время от момента возникновения проблемы до ее решения. Сокращение TTR требует инвестиций в эффективные процессы выпуска и отката изменений.
- Дежурства: во многих странах дежурства требуют дополнительной оплаты (например, в Швеции за дежурство платят на 40% больше, даже если инцидентов не было, а в выходные — еще больше). Для ротации дежурств обычно требуется 5–8 сотрудников, которые достаточно хорошо знают систему для устранения неполадок.
- Автоматизация — например, для 99,999 (26 секунд простоя в месяц) человек физически уже не успеет среагировать. За это время невозможно: обнаружить проблему, разбудить сотрудника, заставить его открыть ноутбук, найти причину, создать исправление и выпустить его. Поэтому высокодоступные системы требуют автоматического обнаружения и устранения ошибок.
- Процессы: процессы создаются не для поддержки креативности, а для защиты от человеческих ошибок, предвзятости и медлительности. Они добавляют надежность ценой бюрократии: контроль качества (QA) как привратники, SRE как надзиратели, менеджеры как пожарные. Избыточные процессы могут привести к уходу лучших специалистов. Внедряйте процессы осознанно, сопоставляя затраты с рисками, и регулярно пересматривайте их. Риск: лучшие специалисты уйдут из-за рутины.
Правда ли каждая девятка делает систему в десять раз дороже?
В отличие от времени простоя, стоимость добавления девяток не поддается такой прямой математике и зависит от продукта, технологий, архитектуры, персонала и многих других факторов.
Но ясно одно: высокая надежность стоит дорого. Эти затраты должны соотноситься с бизнес-целями и быть обоснованы прибылью от этого сервиса.
Как утверждает Алекс Идальго в своей книге «Достижение целей по повышению уровня обслуживания«:
«Стремление к идеальной надежности не только невозможно, но и невероятно дорого. Ресурсы, необходимые для приближения к 100%, растут по кривой, которая круче линейной. Поскольку достичь 100% невозможно, вы можете потратить бесконечные ресурсы и так и не добиться цели».
На практике главная сложность — убедить высшее руководство, что перфекционизм контрпродуктивен. Для этого я использую мемы вроде этого:

[Представьте мем с надписью: «Хочешь пять девяток? Готовься к тому, что твоя система будет стоить как пять самолетов!»]
История из жизни
Несколько лет назад я присоединился к отделу прямых продаж медиакомпании. Это был аналог Netflix, но с контентом, принадлежащим американскому медиагиганту. До моего прихода у продукта были серьезные проблемы с надежностью. Отзывы пользователей сводились к одному: они обожали контент, но ненавидели платформу.
У нас была проблема с надежностью.
Компания поступила как типичная крупная американская корпорация: решила засыпать проблему деньгами 💸💸💸
Решение? Нанять инженеров по надежности (SRE). Так я и появился.
Когда я услышал, что технический директор (CTO) хочет пять девяток, я усмехнулся (напомню: сервис может быть недоступен всего 26 секунд в месяц, а мы говорим о продукте уровня Netflix, а не об аэропортовой системе управления воздушным движением, банке или больничной информационной системе). 😄
При этом вся инженерная команда была в разы меньше, чем у Netflix. А Netflix к тому моменту уже много лет работал над надежностью.
Тогда я понял: нас ждет тяжелая битва. Но как снизить его ожидания?»