В предыдущей статье мы рассмотрели обнаружение аномалий с помощью правила 3 сигм в Influx. Теперь сделаем то же самое в Grafana + Prometheus.
Краткое напоминание: правило 3 сигм
Правило трех сигм утверждает, что приблизительно все наши «нормальные» данные должны находиться в пределах трех стандартных отклонений (σ) от среднего значения (μ) ваших данных. В этой статье исследуется, как мы можем измерять стандартные отклонения от среднего значения и настраивать оповещения, когда это значение превышает 3.0 (другими словами, когда наш Z-показатель превышает 3.0), используя Grafana в сочетании с Prometheus.
- Рассчитаем Z-показатель:
(x - μ) / σ - Настроим алертинг при
Z > 3.0
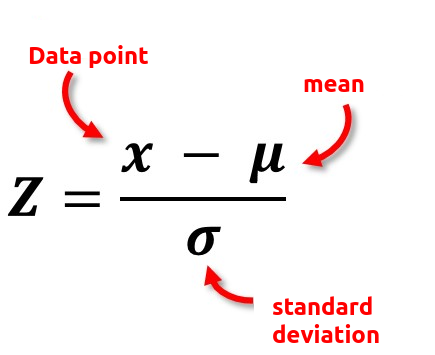
Формула Z-показателя
Итак, нам необходимо запросить в Grafana три параметра:
- Точку данных для описания интервала диапазона (x)
- Среднее значение наших данных за более длительный период времени (μ)
- Стандартное отклонение за тот же (более длительный) период времени (σ)
Для целей обсуждения давайте сосредоточимся на метрике «node_disk_writes_completed_total». Среднее значение и стандартное отклонение очень легко извлечь с помощью встроенных функций в Prometheus:
Среднее значение за период времени (avg_over_time(range-vector)):
avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d]))
Стандартное отклонение за период времени (stddev_over_time(range-vector)):
stddev_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d])
Приведенные выше два выражения дадут нам среднее значение и стандартное отклонение, рассчитанные за один день – отсюда и переменная диапазона [1d].
Последний элемент головоломки – это получение точки данных… «x» в нашей формуле выше. Я решил эту задачу, просто взяв еще одно среднее значение за период времени, но для интервала диапазона, равного переменной дашборда, а не фиксированного значения в 1 день, как выше:
avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[$__rate_interval]
Обратите внимание на использование [$__rate_interval] выше: https://grafana.com/docs/grafana/latest/datasources/prometheus/#using-__rate_interval
Собираем все вместе
Реализуя нашу формулу, мы получаем следующий запрос:
(avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[$__rate_interval])-avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d]))/stddev_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d])
Результаты
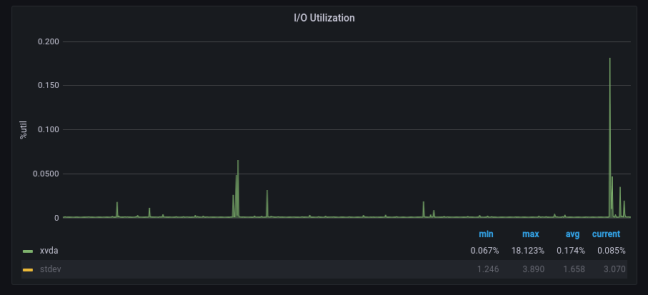
Приведенные выше запросы были выполнены для источника данных, график которого выглядел следующим образом:
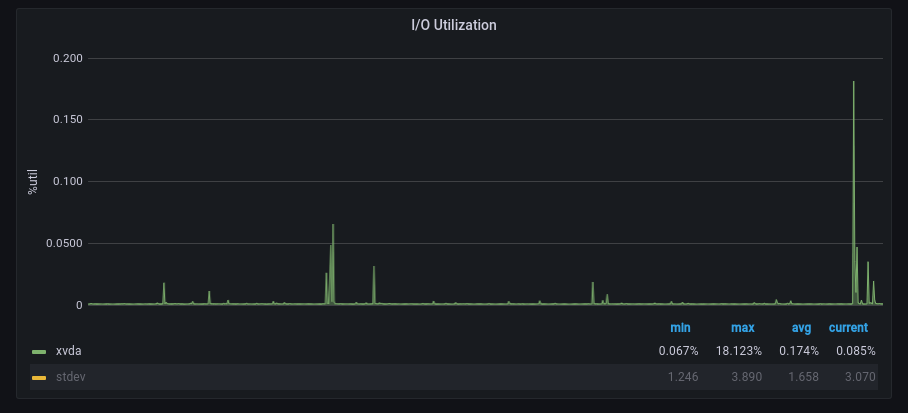
График с большим выбросом справа
Обратите внимание на большой выброс справа – мы хотели бы получать оповещения о таком большом выбросе, но не обязательно о меньших выбросах слева. Вот что дает нам проверка на аномалии:
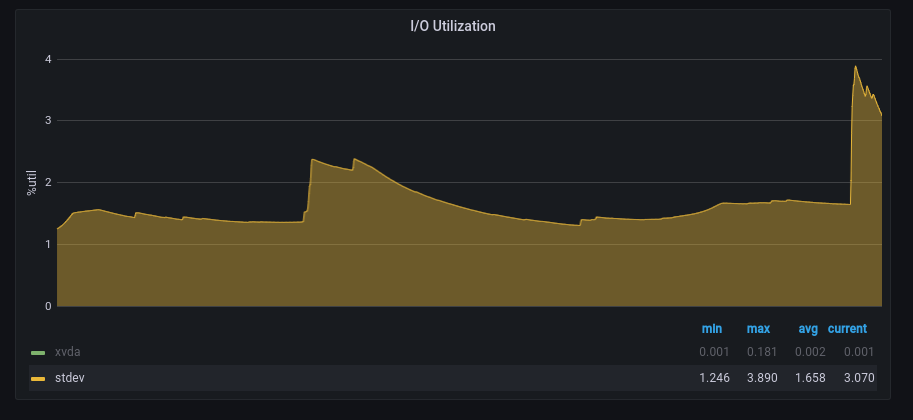
График Z-показателя с порогом
Если установить порог >= 3, то меньшие выбросы не вызовут оповещения, а наш большой выброс – вызовет, поскольку он является значительным.
Другой пример – следующий временной ряд:
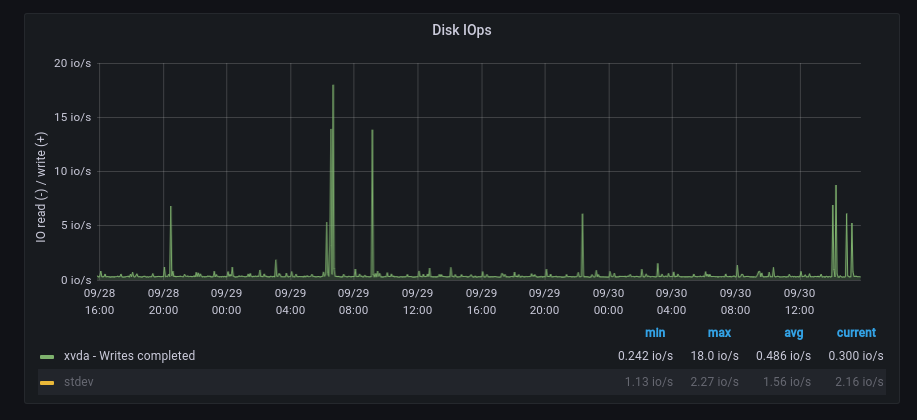
График с множеством выбросов
Данный временной ряд имеет гораздо больше выбросов (в терминах сигналов ряд является более «зашумленным»), поэтому мы не хотели бы использовать статический порог, который срабатывает на каждый выброс, а только на выбросы, выходящие за пределы нормы. Применяя наш запрос на аномалии, мы получаем:
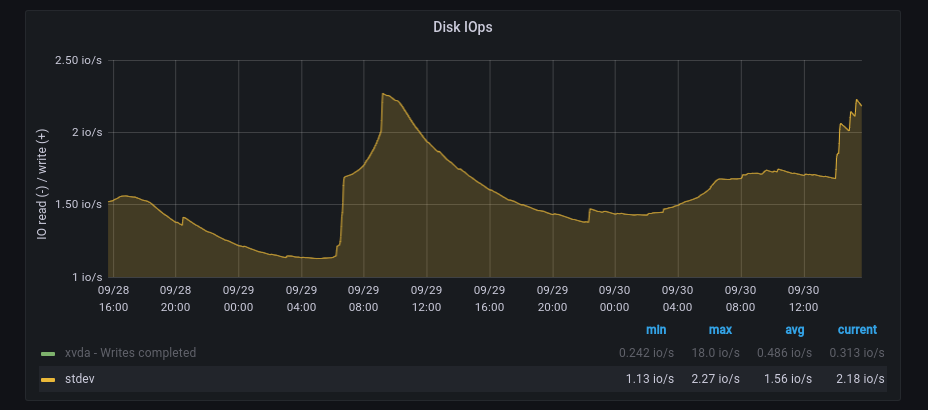
График Z-показателя для зашумленных данных
Обратите внимание, как результаты приближаются к Z-показателю 2.5, но никогда не превышают наш порог в 3, автоматически учитывая тот факт, что сигнал более зашумлен. Еще один интересный момент заключается в том, что запрос на аномалии автоматически обрабатывает два различных сценария, как показано ниже:
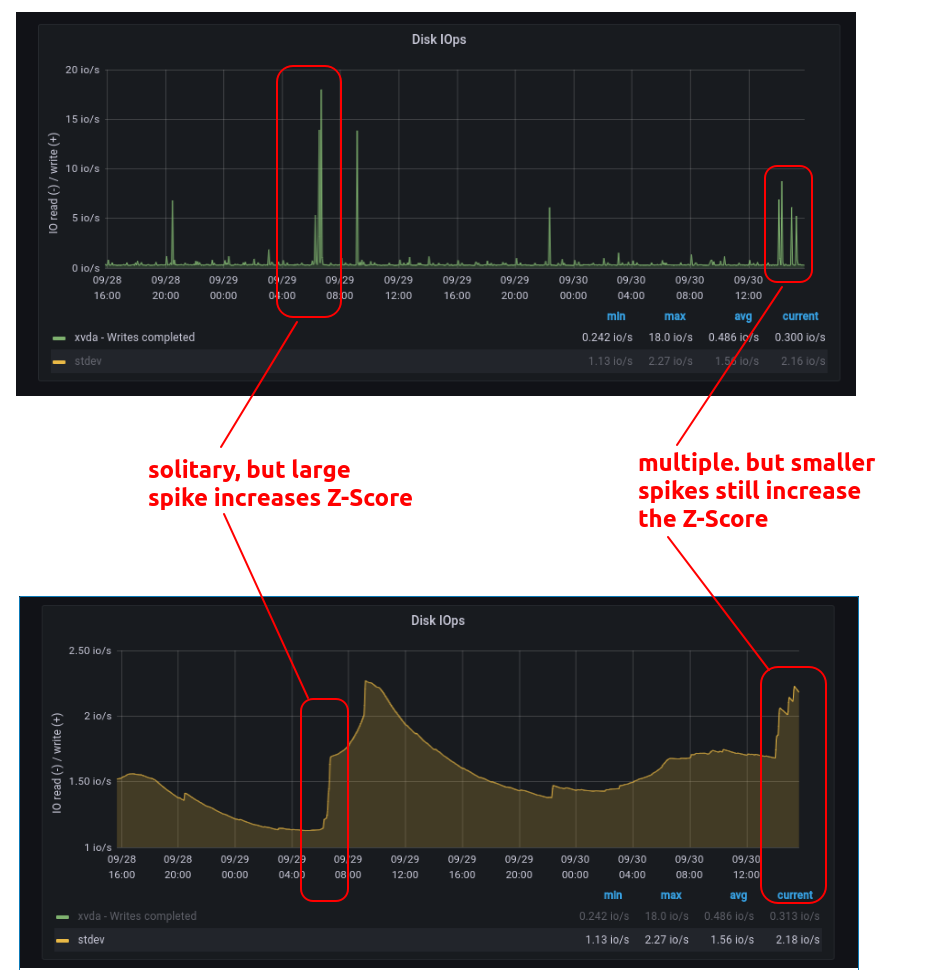
Сравнение двух сценариев
Оригинал: Grafana Prometheus: Detecting anomalies in time series